
Does your company receive data payloads as attachments in emails? Do people manually download these, massage them in Excel, and upload them to Google Drive for wider internal use? It sure would be great if you could get the data through an API in an automated way but sometimes that's just not the way the cookie crumbles.
We've developed a lightweight system for automating receiving and processing payloads attached to emails to eliminate manual processing and get your data into your warehouse quickly and efficiently.
Managing and processing data delivered via email can be a daunting task, particularly when the data comes in various formats and structures. This blog post outlines an automated data processing pipeline designed to tackle these challenges efficiently. The pipeline utilizes AWS Simple Email Service (SES), Amazon S3, Amazon Simple Queue Service (SQS), a custom Python scripts to standardize and track the data. Then Sling is used to load the data into a data warehouse. By implementing this pipeline, businesses can streamline their data management workflows, ensuring consistency and readiness for analysis.
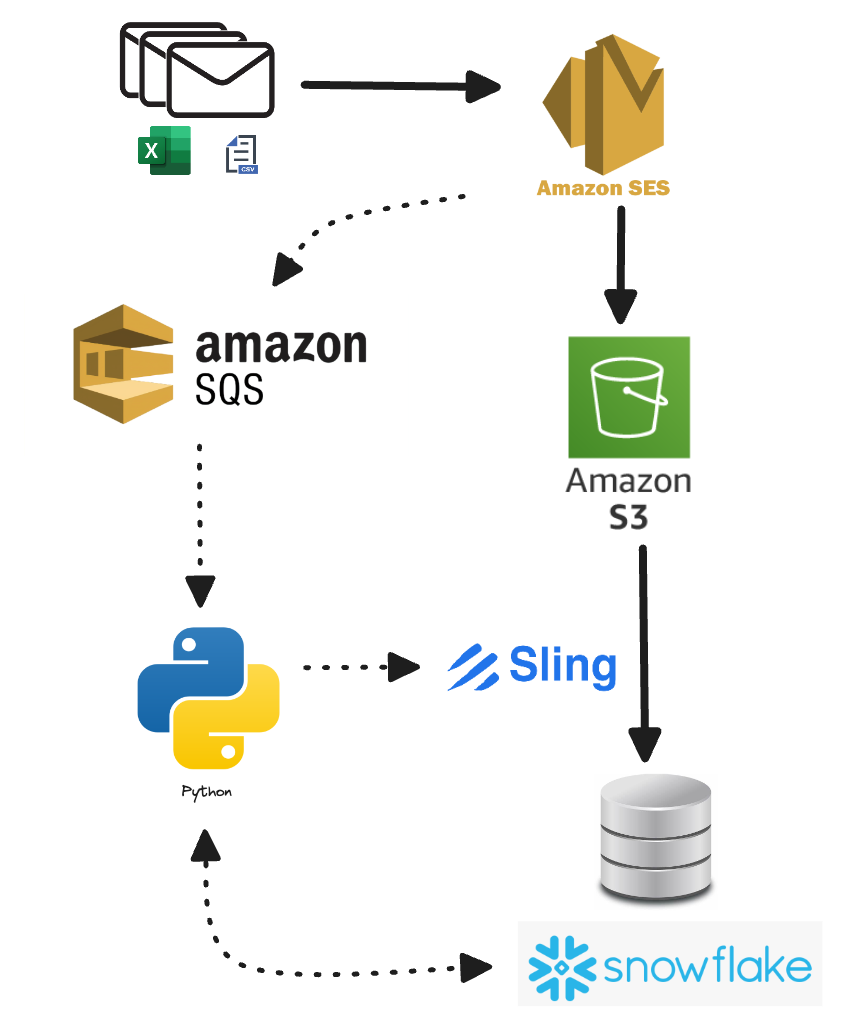
Email Reception
When an email is sent to a email address with a custom domain (such [email protected]), AWS SES handles this process. SES receives the email and stores the message in its raw format, with the attachments (Excel or CSV format) in an Amazon S3 bucket. This storage method ensures that the original data is preserved for any future reference or reprocessing needs. Additionally, SES has the capability to queue the message in an SQS queue, setting the stage for the next steps in the automated pipeline.
Queue Monitoring & Processing
Once the email is written to S3 and a message pushed in our SQS queue, it is ready for consumption. This is where the Python script comes into play. It runs multiple times a day to check the SQS queue for any new messages and when it finds new messages, it starts processing them right away. By polling the SQS queue regularly, the script ensures that no messages are left waiting for too long, which helps keep the data processing timely and efficient.
def receive_messages(queue):
s3_objects : List[S3Object] = []
try:
messages = queue.receive_messages(MaxNumberOfMessages=10)
# process all messages in queue
for msg in messages:
log.info("Received message: %s", msg.message_id)
data = json.loads(msg.body)
msg_data = json.loads(data['Message'])
log.debug(f"message payload -> {json.dumps(msg_data)}")
s3_bucket = jmespath.search('receipt.action.bucketName', msg_data)
s3_key = jmespath.search('receipt.action.objectKey', msg_data)
yield S3Object(s3_bucket, s3_key)
except ClientError as error:
log.exception("Couldn't receive messages from queue: %s", queue)
raise error
Once it grabs a message from the queue, the script uses specific criteria—like the sender's email, the email subject, or the attachment details—to decide which Processor to use. This method makes the pipeline scalable and able to handle different data providers automatically, without needing manual intervention.
Each data provider has a custom Python class dedicated to processing its specific data format. For instance, retailers like Gucci or Sephora send standardized data reports to their customers. Having a unique processor for each provider ensures that the data is parsed accurately, regardless of its initial structure. This flexibility is essential for dealing with the diverse data formats that different wholesalers use.
def process_email(self, s3_object: S3Object = None, provider: Provider = None):
s3_object.download()
msg = email.message_from_string(s3_object.body)
subject = msg['Subject']
from_ = msg['From']
to = msg['To']
attachments = [sub_msg.get_filename() for sub_msg in msg.get_payload() if sub_msg.get_filename()]
log.info(f'Email (From: "{from_}", To: "{to}", Subject: "{subject}", Files:"{attachments}"')
if provider is None:
if 'sephora' in subject.lower():
if 'Best Seller' in json.dumps(attachments):
provider = ProviderSephora()
else:
log.info('email ignored.')
return
elif 'gucci' in subject.lower():
provider = ProviderGucci()
elif 'ccr' in from_.lower():
provider = ProviderCreedenceClearwaterRevival()
else:
raise Exception(f"could not infer provider from email(from='{from_}', subject='{subject}')")
Data Parsing and Transformation
Once the correct Processor is identified, the script begins parsing and transforming the raw data into a standardized CSV format, a crucial step for preparing the data for the data warehouse. The custom Processor class parses the raw data, which can come in various structures, including pivoted formats.
After parsing, the data is saved as a CSV file, which normalizes the data and ensures consistency across different data sources. This standardized format is essential for the seamless integration of the data into the data warehouse.
Tracking Files Status
To maintain a comprehensive record of all processed files, a new entry is created in the TRACKER table. This table plays a critical role in tracking the status and metadata of each file processed by the pipeline. It includes columns such as:
| Column | Description |
|---|---|
PROVIDER | The name of the data provider (e.g., Amazon, Sephora). |
RAW_FILE_URI | The S3 URI of the raw data file. |
CSV_FILE_URI | The S3 URI of the processed CSV data file. |
TABLE_NAME | The target table name in the data warehouse. |
ORIGIN | The source of the raw data (e.g., email, backfill, api). |
STATUS | The processing status of the file (e.g., PENDING, PROCESSED, SKIPPED). |
CREATED_AT | The timestamp when the record was created. |
PROCESSED_AT | The timestamp when the data was processed. |
UPDATED_AT | The timestamp of the last record update. |
RAW_FILE_SIZE | The size of the raw file in bytes. |
CSV_FILE_SIZE | The size of the processed CSV file in bytes. |
Loading Data into the Data Warehouse
Once the data is in a standardized format and inserted into the Tracker as PENDING, we run another function to run Sling, an an easy-to-use, open-source, lightweight data loading tool. The Python script sets up a Sling Replication configuration to handle the incremental loading of new or updated files into the warehouse. Once triggered, Sling will read directly from S3 and efficiently loads into our data warehouse (Snowflake). We then mark our files as PROCESSED in our tracker.
def load_pending():
tracker = Tracker()
records = tracker.get_records(status='PENDING')
# build sling replication
streams = {}
for record in records:
csv_file_uri = record['csv_file_uri']
table_name = record['table_name']
log.info(f'adding stream {csv_file_uri}')
streams[csv_file_uri] = ReplicationStream(mode='incremental', object=table_name, primary_key='_hash_id')
replication = Replication(
source='btd_s3',
target='btd_snowflake',
streams=streams,
env=dict(SLING_STREAM_URL_COLUMN='true', SLING_LOADED_AT_COLUMN='true'),
debug=True,
)
replication.run()
# set as processed
if len(records) > 0:
log.info(f'setting {len(records)} records as PROCESSED')
tracker.set_processed([rec['csv_file_uri'] for rec in records])
Conclusion
Automating the processing of data delivered via email can significantly streamline data management workflows. By leveraging AWS SES, S3, SQS, Python and Sling, this pipeline ensures that data from various providers is accurately processed, standardized, and loaded into a data warehouse. This setup not only enhances scalability but also provides a robust mechanism for tracking and managing data processing status.